728x90
* 개인적으로 읽고 가볍게 정리해보는 용도로 작성한 글이라 미숙하고 정확하지 않습니다. 양해 부탁드립니다 :D
Transforming Cooling Optimization for Green Data Center via Deep Reinforcement Learning
Cooling system plays a critical role in a modern data center (DC). Developing an optimal control policy for DC cooling system is a challenging task. The prevailing approaches often rely on approximating system models that are built upon the knowledge of me
arxiv.org
- EnergyPlus를 통한 시뮬레이션
- 서버 사이에 cold aisle 넣어두고 이걸로 전체 서버 cooling을 컨트롤
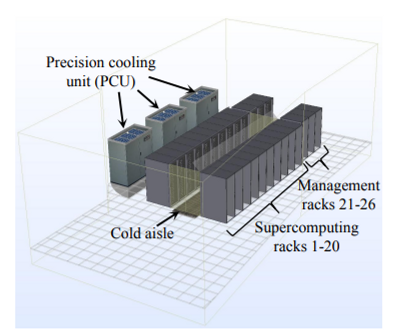
Simulation System model
Data center model
- 서로 다른 크기, 위치와 독립적 cooling system을 가진 data center(DX -직접확장 / Chiller)
- IT Equipment + illumination과 같은 소스에서 발생하는 발열
- ITE 부하는 제곱미터 당 정해진 부하 L(전등 등)과 시간에 따라 달라지는 부하량 a의 곱
- zone 1 load density 4kw, zone 2 2kw
- 작업 부하와 온도를 하나의 튜플로 작성해서 state에 사용
- reward로 PUE와 IT Equipment outlet 온도 제공
- PUE는 최소화, ITE는 일정 수준 이내
Cooling system model
- Action space
- 같은 수냉 기반 / 물을 사용하는 방식이 다름

Problem statement
- 온도 `\T_{amb}\` 와 부하 `\H_{ite}`\ , 시간에 따라 변화하는 tuple 제공
- 냉각수의 5가지 input을 제어하는 것이 목표(위 그림의 Txx - DEC outlet temp, IEC outlet temp, chilled water loop outlet temp, DX cooling coil outlet temp, chiller cooling coil outlet temp)
- PUE의 최소화와 서버 과열의 패널티
- 두 개의 목적 함수
- penalty function(최소화)
- λ - penalty 계수
- Tzi - zone i 에 대한 평균 ITE 온도
- φ - 과열 기준 threshold
- penalty function(최소화)
- 두 개의 목적 함수

Neural end to end cooling control algorithm(CCA)
Batch Learning(Offline learning) / On Policy
- 실시간 데이터를 학습에 추가하는 것은 위험을 감수해야하기 때문에 이 경우 offline learning(batch learning) 사용
- batch 학습에도 두 가지 종류가 있는데 on Policy와 off policy
- simulation 시간에 따른 비용이 높아서 off policy 사용
- Off-policy algorithms generally employ a separate behavior policy, which is independent of the policy being estimated, to generate the training trace; while on-policy directly uses control policy being estimated (in the real control practice or more likely in a simulator) to generate training data traces
CCA with offline trace
- 일반적인 강화학습 접근에서 미래의 보상 데이터도 평가에 사용되는 것과는 달리
- 여기에서는 미래 보상 데이터는 안 쓰고 작업부하와 날씨 데이터가 시스템 전환을 정의
- 어떤 결과가 나왔을 때 적용되는데 시간이 걸리므로 이번 시간에 관찰한 결과가 다음 시간에 반영되도록 시간 축소(?)
- 데이터는 전부 N 시간 동안의 시계열
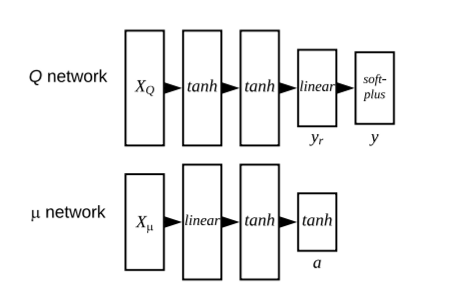
- Q-Network
- 현재 상태 s 에서 행동 a를 취했을 때의 비용 출력
- 재귀적인 의사결정 시도 → 이전의 상태와 동작들도 고려함(?)
- MSE
- Policy Network
- 현재 상태 s에서 행동 a를 취했을 때 Q를 출력
- 초반에 validation error가 작은 것은 오류가 아님. 학습 덜 돼서 그렇다.
Neural Network Design
- Q-Network
- activation function으로 tanh 를 사용하는 두 개의 hidden layer
- linear output layer
- 음수 reward 출력
- 실제 y 데이터와 예측된 yr 데이터간의 간극을 줄이는 것을 목표로 함
- Policy Network
- linear activation function과 tanh activation function을 사용하는 두 개의 hidden layer
- 다음 control action인 a를 출력
- Q-Network의 loss function 최적화
- 모든 데이터를 (-1, 1) 범위로 정규화해서 tanh activation function에 맞추고, 실제 에너지와 온도 값을 계산해야할 때 비정규화함.

- Data
- state data series, action, reward 데이터 필요
- Q-NN input
- policy network input
- loss data y 계산을 위한 PUE와 온도 데이터
- initialize
- Q network 와 policy network 생성
- weight parameter random initialize
- epoch / mini batch에 따라서
- Q NN 파라미터 최적화
- policy network 파라미터 최적화
- swap / evaluation
- return
- 최적 가중치 파라미터로 세팅된 Q network와 policy network
728x90
'🐬 ML & Data > 📘 논문 & 모델 리뷰' 카테고리의 다른 글
| [Paper Review] Mamba - Linear Time Sequence Modeling with Selective State Spaces 2 (1) | 2024.12.11 |
|---|---|
| [Paper Review] Mamba - Linear Time Sequence Modeling with Selective State Spaces 1 (1) | 2024.12.11 |
| [Model Review] TadGAN(Time series Anomaly Detection GAN) (0) | 2023.05.17 |
| [Model Review] YOLOv5 + Roboflow Annotation (0) | 2023.03.14 |
| [Model Review] MobileNet SSD 논문 퀵 리뷰 (1) | 2022.12.13 |