
Elasticsearch에 데이터를 적재할 때, 어떤 방식으로 데이터를 적재할지에 대한 세팅을 해줄 수 있다.
Elasticsearch는 역색인을 기반으로 데이터를 인덱싱하기 때문에, 역색인의 기준이 되는 단어(token)들을 어떻게 토큰화하는지에 따라서 검색의 결과도 달라질 수 있다.
이렇게 Token을 생성하는 규칙을 담은 설정을 Index Template라고 부른다.
Elasticsearch의 Index Template은 크게 Setting의 영역과 Mapping의 영역으로 나누어진다. 오늘은 Setting의 구성요소인 Analyzer, Tokenizer, Filter에 대해 이야기해보려고 한다!
- logstash에서 elasticsearch로 데이터를 보내줄 때 json 형태로 미리 setting 파일을 만들어서 document template를 지정할 수도 있다.
A. Elasticsearch Analyzer
- analyzer → elasticsearch에서 필드 인덱싱 / document화할 때 텍스트를 분석하는 엔진
- 1개의 tokenizer / 다수의 filter
- filter
- CharFilter : 입력된 문자열에 대한 불필요한 문자 normalization
- 공백, 콤마 등의 문자 삭제
- TokenFilter : tokenizer로 분해된 token에 대한 filter
- CharFilter : 입력된 문자열에 대한 불필요한 문자 normalization

흐름을 보면, 먼저 Text가 들어오면 Character Filter를 거쳐 normalization이 되고, Tokenizer를 거쳐서 문장을 토큰화하고 난 뒤 각 토큰에 대해서 Token Filter가 후처리한 뒤 색인을 생성한다.
kibana - dev tools에서 미리 실험해볼 수 있다. 아래 템플릿에 각각 대입해보면 되겠다.
get _analyze
{
"text": "{EXAMPLE TEXT}",
"char_filter": ["{CHARACTER FILTER}"],
"tokenizer": {
"type": "{TOKENIZER}"
},
"filter": ["{TOKEN FILTER}"]
}1. CharFilter
입력된 문자열에 대한 전처리 단계라고 보면 된다.
- html_strip - html 태그를 삭제해주는 filter
"char_filter": {
"my_char_filter": {
"type": "pattern_replace",
"pattern": "(\\d+)-(?=\\d)",
"replacement": "$1_"
}
}- mapping - 특수문자, 불용어 등을 다른 표현방식으로 1대 1 매핑시켜줌(수동)
"char_filter": [
{
"type": "mapping",
"mappings": [
"٠ => 0",
"١ => 1",
"٢ => 2",
"٣ => 3",
"٤ => 4",
"٥ => 5",
"٦ => 6",
"٧ => 7",
"٨ => 8",
"٩ => 9"
]
}
]- pattern_replace - 특정한 문자 패턴을 다른 것으로 대체해줌(수동)
- ex) 123-678 ⇒ 123_678
"char_filter": {
"my_char_filter": {
"type": "pattern_replace",
"pattern": "(\\d+)-(?=\\d)",
"replacement": "$1_"
}
}- ex) CamelCase replacement
"char_filter": {
"my_char_filter": {
"type": "pattern_replace",
"pattern": "(?<=\\\\p{Lower})(?=\\\\p{Upper})",
"replacement": " "
}
}2. Tokenizer
전처리를 마친 문자열을 토큰화하는 단계이다. 아래 사진은 "how to tokenize string?" 문장을 standard tokenizer로 토큰화한 결과를 보여준다.
Elasticsearch에서 지원하는 수많은 토크나이저가 있다. 설정하지 않으면 설정되는 기본 tokenizer type은 Standard이다.
Word Oriented Tokenizers(단어 지향 토크나이저)
- Standard Tokenizer : 유니코드 텍스트 분할 알고리즘에 따라 토큰화
- Letter Tokenizer : 문자(letter)가 아닌 것을 만날 때마다 단어로 토큰화
- Lowercase Tokenizer : Letter tokenizer와 같은 방식으로 동작 + 알파벳을 전부 소문자로
- Whitespace Tokenizer : 공백을 만날 때마다 단어로 토큰화
- UAX URL Email Tokenizer : url과 email을 단일 토큰으로 인지하는 standard tokenizer
Partial Word Tokenizers(부분 단어 토크나이저)
- N-Gram Tokenizer : 공백이나 문장부호 등을 만나면 텍스트를 단어로 분해 -> 각 단어의 n-gram 반환
- ex) quick => [qu, ui, ic, ck]
- Edge N-Gram Tokenizer : N-Gram과 기본적으로 같으나 N-Gram을 적용할 때 첫 문자를 포함하는 부분 문자열 tokenizing
- ex) quick => [q, qu, qui, quic, quick]
Structed Text Tokenizer(구조화된 텍스트 토크나이저)
- Keyword Tokenizer : 주어진 텍스트 전체를 하나의 토큰으로 토큰화
- Pattern Tokenizer : 정규식으로 일치하는 패턴이 있을 때마다 토큰화
- Path Tokenizer : 파일 시스템 경로와 같은 계층적 값을 / 를 기준으로 분할해서 상위 경로들을 토큰화
- ex) /foo/bar/baz→ [/foo, /foo/bar, /foo/bar/baz ]
이외에도 언어별로 tokenizer를 추가 플러그인으로 설치해서 사용할 수 있는 등 수많은 tokenizer이 존재한다. (한국어 토크나이저인 Nori https://www.elastic.co/guide/en/elasticsearch/plugins/8.8/analysis-nori.html 처럼) 더 많은 내용은 공식 문서에서!
Tokenizer reference | Elasticsearch Guide [8.8] | Elastic
A tokenizer receives a stream of characters, breaks it up into individual tokens (usually individual words), and outputs a stream of tokens. For instance, a whitespace tokenizer breaks text into tokens whenever it sees any whitespace. It would convert the
www.elastic.co
Analysis plugins | Elasticsearch Plugins and Integrations [8.8] | Elastic
Analysis plugins extend Elasticsearch by adding new analyzers, tokenizers, token filters, or character filters to Elasticsearch. Core analysis pluginsedit The core analysis plugins are: ICU Adds extended Unicode support using the ICU libraries, including b
www.elastic.co
3. Token Filter
Tokenizer을 적용한 뒤 분할된 Token들에 대한 후처리 작업이다. 정말 종류가 너무 대박 많기 때문에 하나하나 설명하지는 않겠다.
Token filter reference | Elasticsearch Guide [8.8] | Elastic
Token filter referenceedit Token filters accept a stream of tokens from a tokenizer and can modify tokens (eg lowercasing), delete tokens (eg remove stopwords) or add tokens (eg synonyms). Elasticsearch has a number of built-in token filters you can use to
www.elastic.co
B. Kibana에서 Template 설정하기
Kibana에서 index template를 생성할 수 있다. UI가 잘 되어있으니 따라해보자.
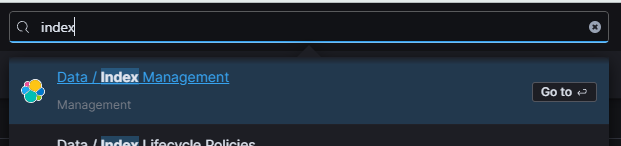

검색창에 index를 검색하면 Index Management 페이지가 있다. 여기에서 Index Template 탭을 선택하고 Create Template를 누른다.
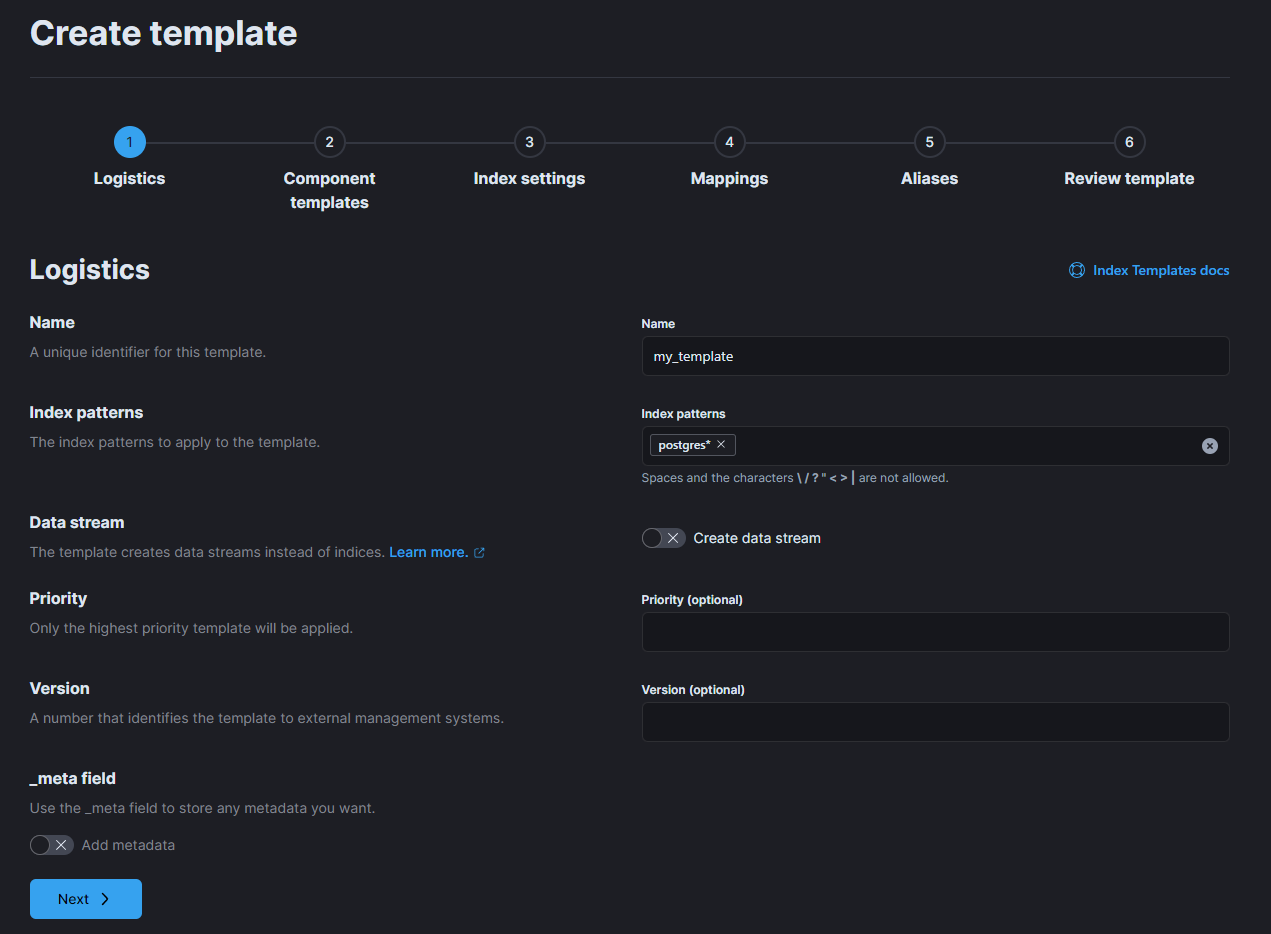
이름과 이 템플릿을 적용할 index pattern을 설정해준다. 나는 logstash를 통해서 새 index 이름으로 postgres를 만들어줄 것이기 때문에, 패턴을 위와 같이 적용시켰다.
Component templates를 넘어간다. 사실 아직 쓸 일이 없었다^^... 쓸 일이 생기면 추후 추가예정
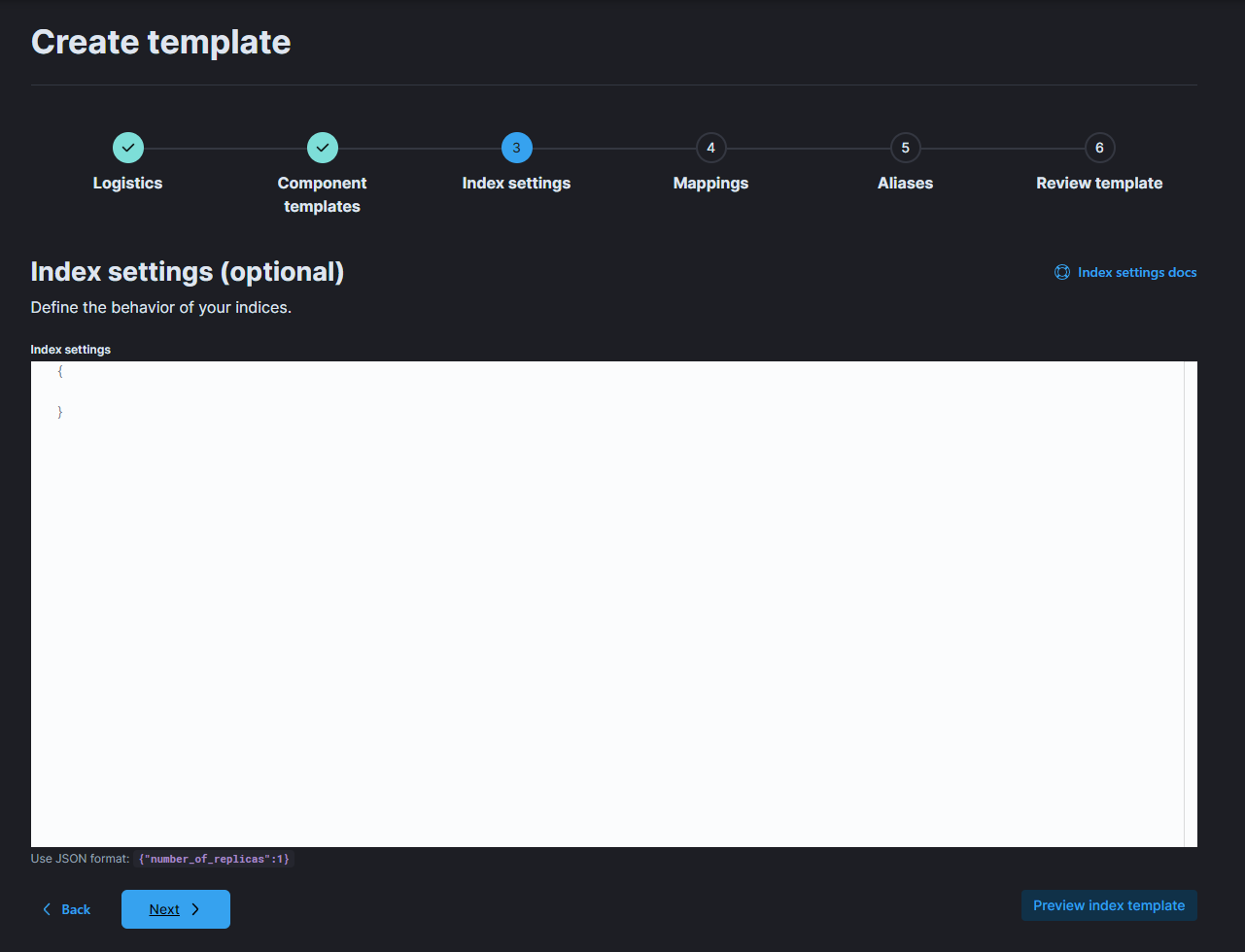
이 부분에 아까 그 analyzer를 정의한다. 예시는 아래와 같다.
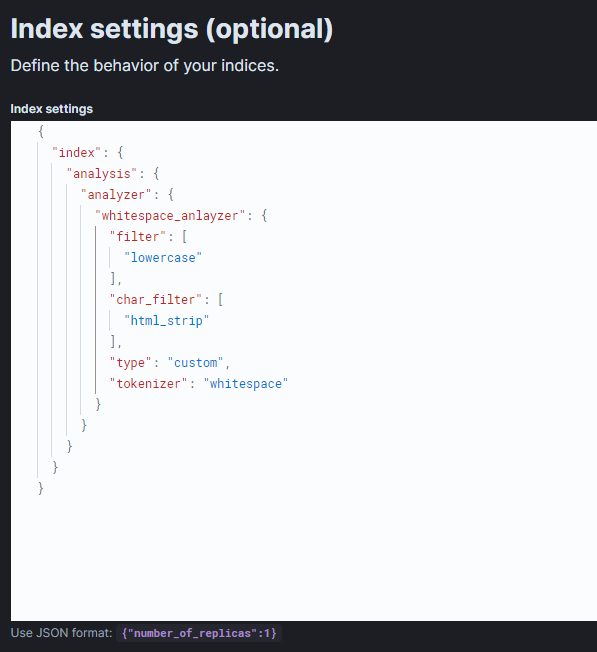
이렇게 쓰면 character_filter는 html_strip, tokenizer는 whitespace, token filter는 lowercase를 쓰는 커스텀 analyzer를 생성한 것이다. 우측 하단 Preview index template를 누르면 에러가 나는지 문법이 틀리지는 않았는지 메세지를 볼 수 있다.
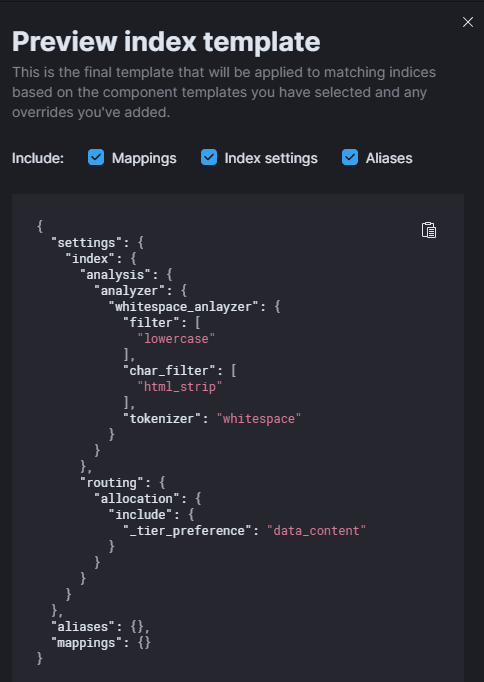
아직 끝나지 않았다... 적어도 mapping까지는 해줘야 제대로 돌아가는 것을 볼 수 있다. mapping에 대해서는 다음 포스팅에서 다루도록 하겠다. 끗!
'🐥 Web > ❔ Back-end | etc.' 카테고리의 다른 글
| [PostgreSQL] Windows 외부 접속 허용 설정 및 외부 접속 방법 (1) | 2023.11.03 |
|---|---|
| [Elasticsearch] Index Template 구성하기 with Kibana & Logstash (2) - Mapping 기초 (0) | 2023.07.14 |
| [Elasticsearch] Logstash를 통해 PostgreSQL과 Elastic Stack 연동하기 (0) | 2023.06.29 |
| [Elasticsearch] Logstash 사용해보기 (0) | 2023.06.29 |
| [Elasticsearch] Elasticsearch 기본 개념 및 설치, kibana 연동하기 (1) | 2023.06.29 |