본의 아니게 오랜만에 라이트 머신러닝 글을 올리게 되었네요! 이번 세션에서는 저번에 예고했다싶이 앙상블 학습에 대해서 알아보려고 하는데요, 여러분은 앙상블하면 무엇이 떠오르시나요? 솔직히 저는 음악이 가장 먼저 떠올랐는데요, 사실 비슷한 개념이기는 합니다.
이번 세션에서는 여러 개 분류기를 합쳐 좋은 성능을 내는 앙상블 학습의 정의와 종류 중 하나인 다수결 투표에 대해서 알아보도록 하겠습니다!
A. 앙상블 학습
앙상블 학습(ensemble learning)은 여러 개의 분류기를 하나의 메타 분류기로 연결해서 더 좋은 성능을 이끌어내는 기법입니다. 앙상블 학습을 위한 분류기를 만들기 위한 방법은 여러가지가 있습니다. 일단 먼저, 앙상블의 작동 원리와 왜 더 성능이 좋은지에 대해서 알아보도록 하겠습니다.
먼저, 가장 인기있는 앙상블 방법인 과반수 투표(majority voting) 방식에 대해서 이야기해보도록 하겠습니다. 이름에서 알 수 있듯이 분류기의 과반수가 예측한 클래스 레이블을 선택하는 방법입니다.
과반수 투표는 이중 클래스 분류에 해당하지만 다중 클래스 문제에서도 일반화가 가능합니다. 이를 다수결 투표(plurality voting)이라고 합니다. 이 경우에는 최빈값을 선택합니다. 아래 그림에서 과반수 투표와 다수결 투표의 개념을 확인하실 수 있습니다. 각각의 모양은 클래스 레이블을 나타냅니다.

훈련 세트를 사용해 m개의 다른 분류기를 훈련시킵니다. 이것을 C라고 할게요. 그리고 앙상블 방법에 따라 여러 알고리즘을 사용해 구축을 하거나 분류 알고리즘을 같은 것을 사용하고 훈련 세트의 부분 집합을 달리해 학습할 수도 있습니다. 유명한 앙상블 방법 중 하나는 랜덤 포레스트(random forest)입니다.

과반수 투표나 다수결 투표로 예측하려면 개별 분류기의 예측 레이블을 모아서 가장 많은 표를 받은 레이블 y hat을 선택합니다. 식으로 나타내면 대강 아래와 같습니다.

예를 들어 클래스 1이 -1이고 클래스 2가 +1이면 과반수 투표 예측은 아래와 같습니다.

자, 그럼 앙상블 학습이 왜 더 성능이 좋은지를 설명하기 위해 조합 이론을 적용해보겠습니다. 예를 들어서, 이진 분류 작업을 할 때 동일한 에러율 e를 가진 n개의 분류기를 생각하보겠습니다. 그리고 모든 분류기는 서로에게 영향을 주지 않고 상관관계 없이 독립적이라고 가정합니다. 이렇게 되면 이 분류기들의 앙상블이 만드는 오차 확률을 이항 분포의 확률 질량 함수로 나타낼 수 있습니다.

여기서 는 이항 계수로 n개 원소에서 k개를 뽑는 조합입니다. 이 식은 앙상블이 틀릴 확률을 계산합니다. 좀 더 구체적인 예로, 에러율 e가 0.25인 분류기 11개로 구성된 앙상블의 에러율은 아래와 같습니다.

이렇게 되면 각각의 분류기의 에러율 0.25보다 앙상블 분류기의 에러율 0.034의 에러율이 확연히 낮은 것을 확인하실 수 있습니다! 만일 에러율이 0.5인 분류기가 짝수 개라 예측이 반반으로 나뉘면 에러로 취급됩니다. 일단, 이상적 앙상블 분류기와 다양한 범위의 분류기를 가진 경우를 비교하기 위해 확률 질량 함수를 구현해보겠습니다.
from scipy.special import comb
import math
def ensemble_error(n_classifier, error):
k_start = int(math.ceil(n_classifier / 2.))
probs = [comb(n_classifier, k) * error**k * (1-error)**(n_classifier - k)
for k in range(k_start, n_classifier + 1)]
return sum(probs)
ensemble_error(n_classifier=11, error=0.25)
ensemble_error 함수를 구현한 후에 분류기 에러가 0.0부터 1.0 사이에 있을 때 앙상블 에러율을 계산하겠습니다. 그리고 앙상블과 개별 분류기 에러 사이 관계를 시각화 해보겠습니다.
import numpy as np
error_range = np.arange(0.0, 1.01, 0.01)
ens_errors = [ensemble_error(n_classifier=11, error=error)
for error in error_range]
import matplotlib.pyplot as plt
plt.plot(error_range,
ens_errors,
label='Ensemble error',
linewidth=2)
plt.plot(error_range,
error_range,
linestyle='--',
label='Base error',
linewidth=2)
plt.xlabel('Base error')
plt.ylabel('Base/Ensemble error')
plt.legend(loc='upper left')
plt.grid(alpha=0.5)
plt.show()
위의 결과 그래프에서 볼 수 있듯 앙상블의 에러 확률은 개별 분류기보다 항상 좋습니다. 하지만, 개별 분류기의 성능, 에러율이 0.5보다 낮아야한다는 조건이 있습니다.
B. 다수결 투표를 사용한 분류 앙상블
1. 간단한 다수결 투표 분류기 구현
다수결 투표에서는 분류 모델의 신뢰도에 가중치를 부여해 연결합니다. 일단 수학적으로 표현한 가중치가 적용된 다수결 투표는 아래와 같이 쓸 수 있습니다.
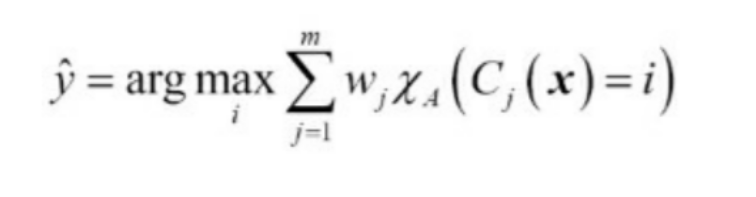
여기서 w는 c라는 분류기에 연관된 가중치이고, y hat은 항상 그랫듯이 앙상블이 예측한 클래스 레이블입니다. 다문자 X 처럼 생긴 카이는 특성함수를 의미합니다. 특성함수는 아래와 같습니다.

이 특성함수를 이용해서 가중치가 동일하다는 가정 하에 위에 나왔던 다수결 투표의 식을 간단하게 쓸 수 있습니다.

argmax와 bincount함수를 이용하면 가중치가 적용된 다수결 투표를 구현할 수 있습니다. bincount함수는 0 이상의 정수로 된 배열을 입력받아 각 정수가 등장하는 횟수를 카운트합니다. 코드는 아래와 같습니다.
import numpy as np
np.argmax(np.bincount([0,0,1], weights=[0.2,0.2,0.6]))이전 세션에서 이야기 했던 적이 있는데, 사이킷런의 일부 분류기는 predict_proba 메서드로 예측 클래스 레이블 확률을 반환할 수 있습니다. 앙상블 분류기가 보정이 잘 되어있다면 클래스 레이블 대신 예측 클래스 확률을 사용하는 것이 좋다고 합니다. 확률을 이용한 다수결 투표는 아래 식과 같습니다.
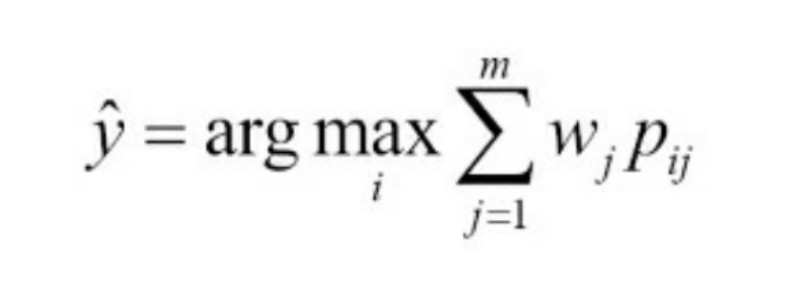
여기서 p는 클래스레이블 i에 대한 j번째 분류기의 예측 확률입니다. 넘파이의 average와 argmax를 이용해서 클래스 확률 기반으로 가중치 적용 다수결 투표를 구현할 수 있습니다.
ex = np.array([0.9,0.1], [0.8,0.2], [0.4,0.6])
p = np.average(ex, axis=0, weights=[0.2, 0.2, 0.6])
print(p)
np.argmax(p)
앞선 친구들을 함쳐서 MajorityVoteClassifier 클래스를 만들어보도록 하겠습니다.
from sklearn.base import BaseEstimator
from sklearn.base import ClassifierMixin
from sklearn.preprocessing import LabelEncoder
from sklearn.externals import six
from sklearn.base import clone
from sklearn.pipeline import _name_estimators
import numpy as np
import operator
class MajorityVoteClassifier(BaseEstimator, ClassifierMixin):
def __init__(self, classifiers,
vote='classlabel', weights=None):
#vote의 기본값은 classlabel. classlabel이면 다수인 클래스 레이블 인덱스, 'probability'이면 확률 합이 가장 큰 인덱스로 예측
#weight는 배열타입. 기본값 None
#Classifier은 앙상블에 사용할 분류기
self.classifiers = classifiers
self.named_classifiers = {key: value for key, value in _name_estimators(classifiers)}
self.vote = vote
self.weights = weights
def fit(self, X, y):
#X = 훈련 샘플 행렬.
#y =
self.lablenc_ = LabelEncoder()
self.lablenc_.fit(y)
self.classes_ = self.lablenc_.classes_
self.classifiers_ = []
for clf in self.classifiers:
fitted_clf = clone(clf).fit(X, self.lablenc_.transform(y))
self.classifiers_.append(fitted_clf)
return self
위 클래스는 sklearn.base의 BaseEstimator 와 ClassifierMixin 클래스를 상속하여 기본적 기능을 갖추고, 여기에는 분류기의 매개변수를 설정 및 반환하는 get_params와 set_params 메서드와 예측 정확도를 계산하는 score 메서드가 포함됩니다.
그리고 predict 메서드를 만듭니다. 이 메서드는 vote='classlabel'로 MajorityVoteClassifier 객체가 만들어지면 클래스 레이블 기반 다수결 투표를 사용해 예측합니다. vote='probability'로 만들어지면 확률 기반 클래스 레이블을 예측합니다.
그럼 계속해서 predict 메서드와 predict_proba 메서드를 추가해보겠습니다.
def predict(self, X):
"""
X : 샘플 데이터 행렬
maj_vote : 예측된 클래스 레이블
"""
if self.vote == 'probability':
maj_vote = np.argmax(self.predict_proba(X),axis=1)
else: # 'classlabel' 투표
# clf.predict 로 결과를 모읍니다.
predictions = np.asarray([clf.predict(X) for clf in self.classifiers_]).T
maj_vote = np.apply_along_axis(
lambda x:
np.argmax(np.bincount(x, weights=self.weights)),
axis=1,
arr=predictions)
maj_vote = self.lablenc_.inverse_transform(maj_vote)
return maj_vote
def predict_proba(self, X):
"""
X : 샘플 데이터 행렬
avg_proba : 샘플마다 가중치가 적용된 클래스의 평균 확률
"""
probas = np.asarray([clf.predict_proba(X)
for clf in self.classifiers_])
avg_proba = np.average(probas, axis=0, weights=self.weights)
return avg_proba
def get_params(self, deep=True):
""" GridSearch를 위해 분류기 매개변수 이름을 반환 """
if not deep:
return super(MajorityVoteClassifier,
self).get_params(deep=False)
else:
out = self.named_classifiers.copy()
for name, step in\
six.iteritems(self.named_classifiers):
for key, value in six.iteritems(
step.get_params(deep=True)):
out['%s__%s' % (name, key)] = value
return out
앙상블에 있는 분류기의 매개변수들에 각각 접근하기 위해 _name_estimators 함수를 사용했고, get_params 메서드를 정의해주었습니다.
2. 다수결 투표 방식을 사용해 예측 만들기
이제 위에서 만든 클래스를 사용해보겠습니다. 일단은 먼저 데이터를 읽어와야하는데요, datasets모듈을 이용해 간편하게 붓꽃 데이터셋을 읽어오겠습니다. 꽃은 Iris-versicolor와 Iris-verginica 두 가지만 분류해보도록 하겠습니다.
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
X, y = iris.data[50:, [1, 2]], iris.target[50:]
le = LabelEncoder()
y = le.fit_transform(y)
X_train, X_test, y_train, y_test =\
train_test_split(X, y,
test_size=0.5,
random_state=1,
stratify=y)이 경우 반은 훈련 데이터로, 반은 테스트 데이터로 설정해주었습니다. 이제 훈련 세트를 사용해서 세 개의 분류기를 훈련해보도록 하죠. 로지스틱 회귀, 결정트리, k-최근접 이웃 분류기를 사용해보겠습니다.
일단 앙상블로 묶기 전에, 10겹 교차검증으로 성능을 평가하고 시작해보도록 할게요. 코드는 아래와 같습니다.
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import Pipeline
from sklearn.model_selection import cross_val_score
clf1 = LogisticRegression(solver='liblinear',
penalty='l2',
C=0.001,
random_state=1)
clf2 = DecisionTreeClassifier(max_depth=1,
criterion='entropy',
random_state=0)
clf3 = KNeighborsClassifier(n_neighbors=1,
p=2,
metric='minkowski')
pipe1 = Pipeline([['sc', StandardScaler()],
['clf', clf1]])
pipe3 = Pipeline([['sc', StandardScaler()],
['clf', clf3]])
clf_labels = ['Logistic regression', 'Decision tree', 'KNN']
print('10-겹 교차 검증:\n')
for clf, label in zip([pipe1, clf2, pipe3], clf_labels):
scores = cross_val_score(estimator=clf,
X=X_train,
y=y_train,
cv=10,
scoring='roc_auc')
print("ROC AUC: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
결과에서 확인하실 수 있듯이 성능은 다들 비슷하네요. 로지스틱 회귀와 k-최근접 이웃 분류기는 왜 파이프 라인으로 훈련했냐면, 이 두 가지는 결정트리와 달리 스케일에 민감하기 때문입니다. 표준화 전처리가 중요한 친구들이죠. 물론 붓꽃 데이터셋 특성이 모두 같은 스케일로 측정되었지만 표준화 전처리를 습관화해봅시다!
이제 우리가 직접 만들어둔 만들어둔 클래스로 앙상블을 만들어 보겠습니다!
# 다수결 투표 (클래스 레이블 카운트)
mv_clf = MajorityVoteClassifier(classifiers=[pipe1, clf2, pipe3])
clf_labels += ['Majority voting']
all_clf = [pipe1, clf2, pipe3, mv_clf]
for clf, label in zip(all_clf, clf_labels):
scores = cross_val_score(estimator=clf,
X=X_train,
y=y_train,
cv=10,
scoring='roc_auc')
print("ROC AUC: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
마지막 줄이 앙상블 입니다. 성능이 확연히 뛰어난 것을 확인할 수 있습니다!
3. 앙상블 분류기 평가와 튜닝
일단 앞선 세션에서 공부했던 ROC를 통해서 MajorityVoteClassifier의 일반화 성능을 확인해볼게요. 테스트 세트를 이용하겠습니다.
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
colors = ['black', 'orange', 'blue', 'green']
linestyles = [':', '--', '-.', '-']
for clf, label, clr, ls \
in zip(all_clf,
clf_labels, colors, linestyles):
# assuming the label of the positive class is 1
y_pred = clf.fit(X_train,
y_train).predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_true=y_test,
y_score=y_pred)
roc_auc = auc(x=fpr, y=tpr)
plt.plot(fpr, tpr,
color=clr,
linestyle=ls,
label='%s (auc = %0.2f)' % (label, roc_auc))
plt.legend(loc='lower right')
plt.plot([0, 1], [0, 1],
linestyle='--',
color='gray',
linewidth=2)
plt.xlim([-0.1, 1.1])
plt.ylim([-0.1, 1.1])
plt.grid(alpha=0.5)
plt.xlabel('False positive rate (FPR)')
plt.ylabel('True positive rate (TPR)')
plt.show()
ROC곡선에서 확인하실 수 있듯이 앙상블 분류기가 테스트세트 에서도 매우 좋은 성능을 내고 있네요. 로지스틱 회귀도 비슷하게 좋은 성적을 내고 있는데, 이는 작은 데이터 셋에서 생기는 높은 분산 때문으로 추정됩니다. 이 이야기가 궁금하신 분들은 로지스틱 회귀 세션을 보고오세요!
여기서는 특성이 두 개만 사용되기 때문에 결정 경계를 확인해볼 수 있습니다. 로지스틱 회귀와 k-최근접 이웃 파이프라인에는 전처리가 있기 때문에 특성을 표준화하는 건 생략해도 됩니다. 아래 코드에서는 결정트리 결정 경계를 다른 모델과 스케일을 맞추기 위해서 사용했습니다.
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
from itertools import product
all_clf = [pipe1, clf2, pipe3, mv_clf]
x_min = X_train_std[:, 0].min() - 1
x_max = X_train_std[:, 0].max() + 1
y_min = X_train_std[:, 1].min() - 1
y_max = X_train_std[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=2, ncols=2,
sharex='col',
sharey='row',
figsize=(7, 5))
for idx, clf, tt in zip(product([0, 1], [0, 1]),
all_clf, clf_labels):
clf.fit(X_train_std, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx[0], idx[1]].contourf(xx, yy, Z, alpha=0.3)
axarr[idx[0], idx[1]].scatter(X_train_std[y_train==0, 0],
X_train_std[y_train==0, 1],
c='blue',
marker='^',
s=50)
axarr[idx[0], idx[1]].scatter(X_train_std[y_train==1, 0],
X_train_std[y_train==1, 1],
c='green',
marker='o',
s=50)
axarr[idx[0], idx[1]].set_title(tt)
plt.text(-3.5, -5.,
s='Sepal width [standardized]',
ha='center', va='center', fontsize=12)
plt.text(-12.5, 4.5,
s='Petal length [standardized]',
ha='center', va='center',
fontsize=12, rotation=90)
plt.show()
앙상블 튜닝을 위해서 개별 분류기의 매개변수를 튜닝하기 전에 GridSearchCV 객체 안의 매개변수에 접근하는 법을 찾기 위해서 get_params 메서드를 호출해볼게요.
mv_clf.get_params()
엄청나게 기네요. 이 길고 긴 반환 값을 잘 살펴보면 개별분류기 속성에 접근하는 방법을 읽어낼 수 있습니다. 예시를 위해 그리드 서치로 로지스틱 회귀의 매개변수 C와 결정트리 깊이를 튜닝해볼게요.
from sklearn.model_selection import GridSearchCV
params = {'decisiontreeclassifier__max_depth': [1, 2],
'pipeline-1__clf__C': [0.001, 0.1, 100.0]}
grid = GridSearchCV(estimator=mv_clf,
param_grid=params,
cv=10,
scoring='roc_auc',
iid=False)
grid.fit(X_train, y_train)그리드 서치 실행이 완료되면 ROC AUC 점수를 출력할 수 있습니다.
for params, mean_score, scores in grid.grid_scores_:
print("%0.3f+/-%0.2f %r"
% (mean_score, scores.std()/2, params))
print('최적의 매개변수: %s' %grid.best_params_)
print('정확도: %.2f' %grid.best_score_)
여기서 확인하실 수 있듯이 규제 강도가 가장 낮을 때 가장 결과가 좋은데, 트리의 깊이는 그리 영향을 주지 않는 것 같네요. 이 데이터를 분할하는데에는 깊이 1로도 충분하기 때문입니다.
여기까지 앙상블 학습과 앙상블 학습의 대표 주자, 다수결 투표에 대해서 알아보았습니다. 앙상블 학습은 머신러닝에 있어서는 꼭꼭꼭 알아야하는 개념이라고 저는 생각합니다. 앞으로 한 세션 더 앙상블에 대한 것을 알아보게 될 텐데요, 이번 세션이랑 함께 읽어주시면 좋을 것 같습니다. 그럼 다음 세션 봬요!

'🐬 ML & Data > 🎫 라이트 머신러닝' 카테고리의 다른 글
| [라이트 머신러닝] Session 18. ROC 곡선과 불균형 데이터 균형 맞추기! (0) | 2020.02.29 |
|---|---|
| [라이트 머신러닝] Session 17. 학습과 검증 곡선, 그리고 그리드 서치 (0) | 2020.02.28 |
| [라이트 머신러닝] Session 16. 파이프라인으로 묶고, 교차 검증으로 모델을 평가하자! (0) | 2020.02.26 |
| [라이트 머신러닝] Session 15. 커널 PCA를 이용한 비선형 매핑 (0) | 2020.02.24 |
| [라이트 머신러닝] Session 14. LDA를 통한 지도학습방식 데이터 압축 (0) | 2020.02.21 |